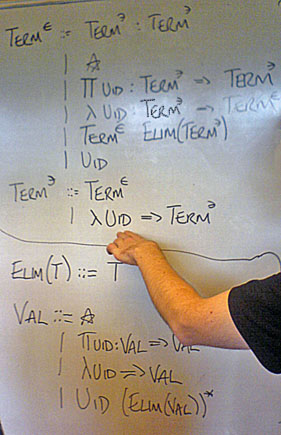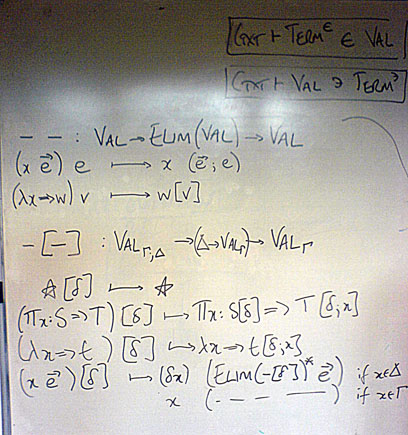Implementing the lambda calculus is, along with buying shoes and then not wearing them, one of my worse habits. Here’s today’s cookery, in literate Haskell. I’m using a certain amount of jiggery pokery.
> {-# LANGUAGE GADTs, KindSignatures, EmptyDataDecls,
> FlexibleInstances, FlexibleContexts
> #-}
I haven’t implemented weak normalization for a while, but Pierre Boutillier and I are currently experimenting with it, reviving my curiosity.
> module Wnf where
> import Control.Applicative
> import Data.Traversable
> import Data.Foldable
Here come all the variations on terms, at once!
> data Form -- reducible stuff or only normal?
> = Rdu | Nrm
> data Stage -- syntax or internal semantic stuff?
> = Syn Form | Sem
> data Direction -- checking or inferring types?
> = Chk | Inf
I’m pretending I have dependent types. It could be worse. Terms are indexed by stage, with syntactic representations for reducible terms and normal forms, and a “semantic” stage for weak normal forms. As ever, I keep parametric in the representation of parameters.
> data Tm :: {-Stage-}* -> {-Direction-}* -> * -> * where
First, the checkable stuff, for all stages.
> -- functions
> F :: Bnd k x -> Tm k Chk x
> -- canonical things
> (:-) :: Con -> [Tm k Chk x] -> Tm k Chk x
> -- noncanonical things
> N :: Tm k Inf x -> Tm k Chk x
Next, the inferrable stuff, likewise.
> -- parameters
> X :: x -> Tm k Inf x
> -- eliminations (of noncanonical stuff)
> (:$) :: Tm k Inf x -> Elim (Tm k Chk x) -> Tm k Inf x
> -- operations
> (:@) :: Op -> [Tm k Chk x] -> Tm k Inf x
Syntactic forms are permitted to use de Bruijn indices.
> V :: Int -> Tm (Syn a) Inf x
Syntactic, reducible forms may have definitions and type annotations.
> (:=:) :: Tm (Syn Rdu) Inf x -> Bnd (Syn Rdu) x ->
> Tm (Syn Rdu) Chk x
> (:::) :: Tm (Syn Rdu) Chk x -> Tm (Syn Rdu) Chk x ->
> Tm (Syn Rdu) Inf x
Now, what’s a binding? Read the rest of this entry »